
[Paper Review] Factually Consistent Summarization via Reinforcement Lerning with Textual Entailment Feedback (ACL 2023)
Published:
Summarization에 RLEF 적용하기
Abstract
텍스트 생성 분야, 특히 요약 분야에서 factual inconsistent 문제는 아직 해결하지 못한 문제이다. 요약 분야에서는 생성한 요약문이 원본 문서와 같은 의미의 내용을 담고 있어야 한다. 해당 논문에서는 textual-entailment 리워드를 통해서 reference-free일 때, factual consistency 문제를 해결하고자 한다.
Introduction
최근의 abstractive summarization 연구들에서는 hallucination, factual inconsistency 문제와 같이 원본 문서와 상반된 내용 혹은 관계 없는 내용이 요약문으로 생성되는 문제가 발생한다. 또한 요약문을 평가할 때 주로 사용하는 ROUGE의 경우 이러한 문제를 탐지하는 역할을 하지 못한다. 따라서 해당 연구에서는 reinforcement learning을 이용하여 이러한 문제를 해결하고자 하는데, 특히 원본 문서와 요약문의 textual entailment (a.k.a. natural language inference, or NLI)를 사용한다. NLI는 요약 태스크만을 위한 태스크가 아니지만 factual inconsistency를 찾는 것에는 효과적으로 알려져있다. 따라서, 신뢰할 수 있는 요약문은 당연히 문서와 entail해야 하므로, 리워드를 entailment로 주는 것은 factually consistent한 요약문을 생성할 때 도움을 준다. 하지만 만약 해당 리워드로만 학습을 한다면 너무 extractive하거나 덜 informative한 요약문을 생성할 수 있다.
따라서, 해당 문제를 해결하기 위해서 Reinforcement Learning with Entailment Feedback (RLEF)을 제안한다. 먼저, 일반적인 크로스 엔트로피를 통해 학습된 요약 모델로부터 시작해서 entailment-based 리워드 기반의 RL로 fine-tuning한다. 학습된 모델은 initial model과 비슷하도록 constrain을 줘서 높은 consistency를 유지한 채, maximum-likelihood objective (MLE)를 통해 기존의 요약 성능은 유지할 수 있도록 한다.
기존의 RL-based 요약 연구들은 먼저 사람의 피드백을 리워드 함수로 사용하였는데, 이런 방법은 피드백이 비싸고 각 태스크를 위한 데이터 수집이 필요하다는 단점이 있다. 하지만 해당 논문에서 제안하는 방법은 사람의 피드백이 필요하지 않고, 데이터를 리워드로 사용하기 때문에 다양한 태스크에서 generic하게 사용할 수 있다. 또 다른 모델은 정답 요약문과 생성된 요약문간의 유사도를 비교하는 연구들이 있는데, 해당 방법은 신뢰할 수 있는 정답 요약문이 필요하다. 하지만 RLEF 방법은 정답 요약문 없이 생성한 요약문만을 사용한다.
Method
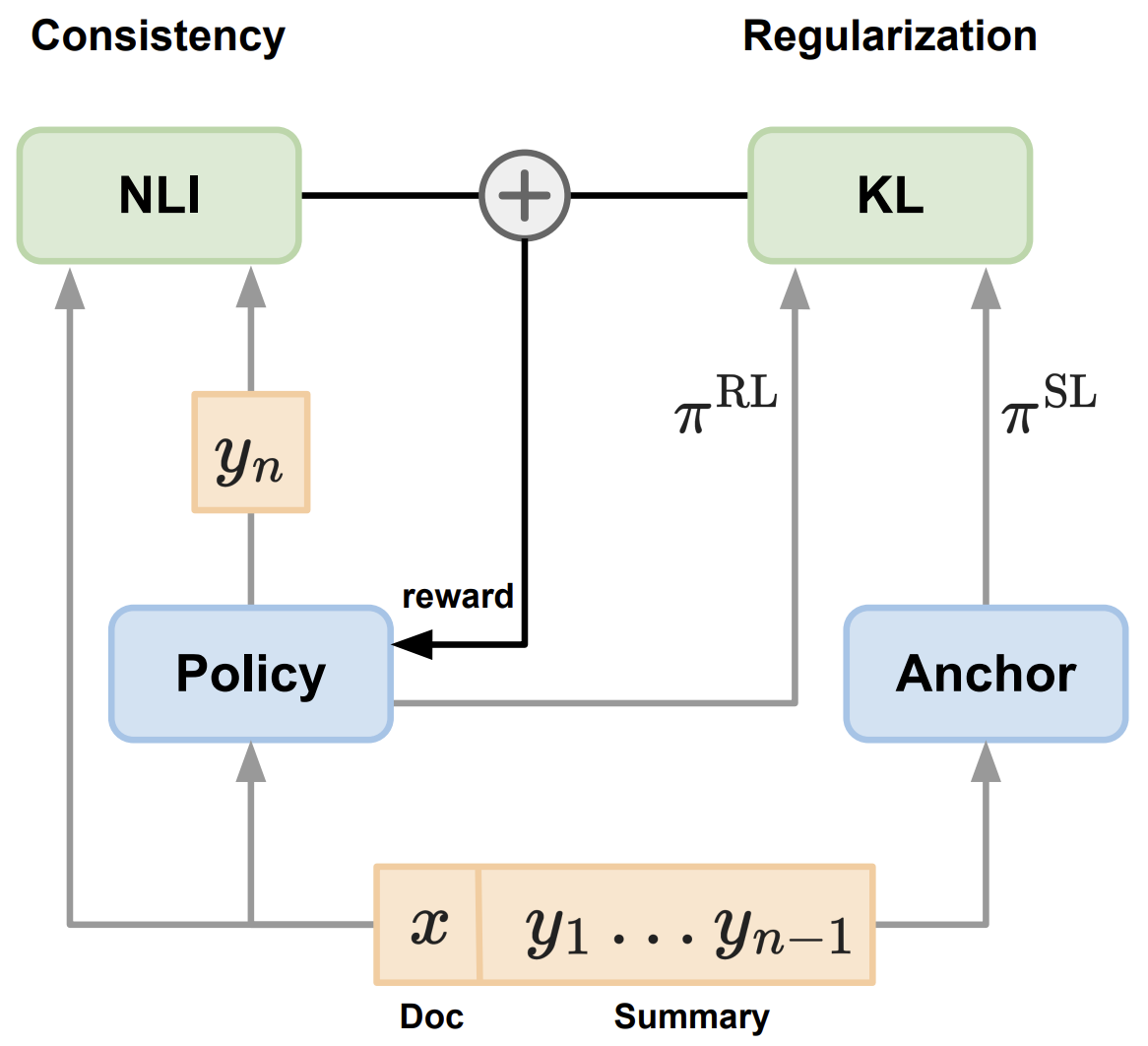
해당 연구에서는 기존의 요약 모델이 가지고 있는 특징들을 유지한 채, entailment-based 리워드로 factual consistency를 향상시키고자 한다. 먼저 RL policy를 학습된 요약 모델로 초기화한 후에 2 가지 시그널을 통해 학습한다. 먼저 entailment 리워드를 통해서 모델이 faithfulness를 향상시키고 anchor model과의 regularization term을 통해서 모델이 요약하는 방법을 까먹지 않도록 학습한다.
RLEF: RL from Entailment Feedback
해당 논문에서는 token-wise generative summarization을 Contextual Markov Decision Process (CMDP)로 정의한다. Context는 input document $x$, state는 $n$-th token generation, action space는 vocabulary $V$, policy $pi$는 $V$의 모든 토큰의 확률 분포로 사용한다. 위의 조건들에 따라 policy는 token-level auto-regressive language model로 사용한다. 해당 RL objective를 통해 축적된 리워드 시그널을 최대화하는 optimal policy를 찾는 것이다.
Rewards
Factual consistency 리워드 시그널을 주기 통해 NLI 분류 모델을 사용한다. NLI 모델의 경우 premise (input document)와 hypothesis (summary) pair로 학습되었으며, sequence-level 리워드를 사용한다. Token-level 리워드는 end-of-sequence (EOS) 토큰을 제외하고 모두 0으로 설정한다. EOS 토큰은 NLI 분류기의 “entailment” 결정의 log-probability를 리워드로 사용한다. $x$는 premise $y$$:n$은 생성된 hypothesis이다.
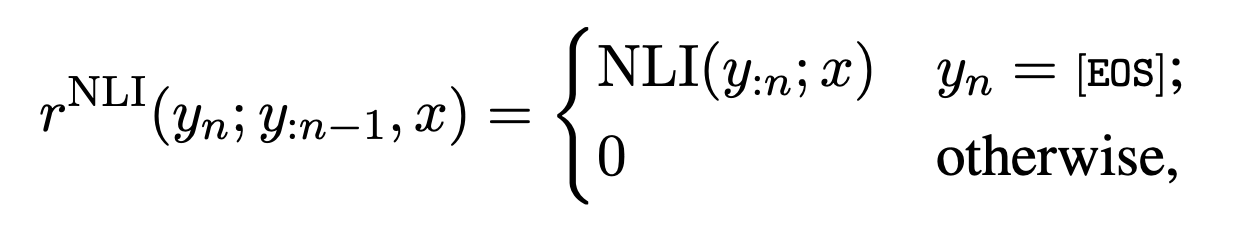
또한 anchor model의 요약 성능을 얻기 위해서 RL-based policy를 supervised anchor policy와의 Kullback-Leibler (KL) regularization을 통해 가깝게 만든다.
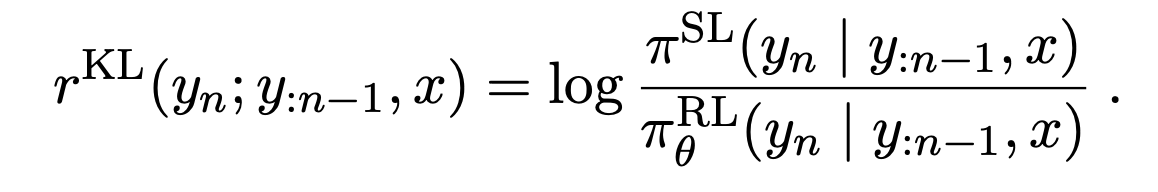
regularization term을 NLI 리워드로 추가함으로써 final token-level 리워드는 다음과 같으며 하이퍼파라미터 $\alpha$ 를 통해서 trade-off 관계인 faithfulness와 anchor policy와의 거리를 조절한다.
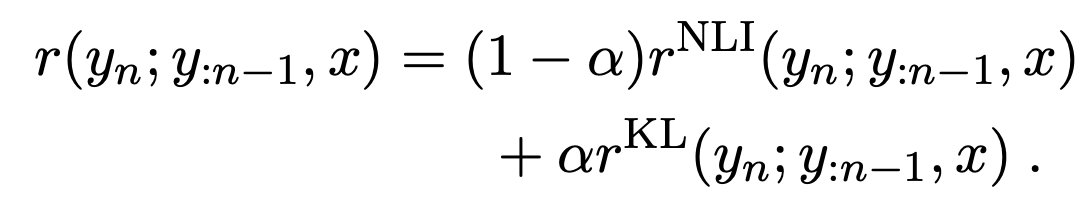
Training Algorithm
Policy를 학습하기 위해서 위의 수식 사용하여 on-policy actor-critic policy gradient (PG)를 사용한다. Anchor model과의 KL penalty 리워드를 통해서 유사도를 유지하기 때문에 이 알고리즘은 regularized PG algorithm이라 할 수 있다. 학습에는 두 가지 모델을 학습하는데, generation model인 policy, value network인 expected value of the policy를 학습한다. Value network의 마지막 레이어가 vocabulary의 분포 대신에 하나의 스칼라 값을 출력하는 것을 제외하고 두 모델의 파라미터를 supervised model로 초기화한다.
RL 학습은 다음과 같다.
- Policy를 통해서 요약문을 생성한다.
- 리워드 시그널을 통해서 생성된 요약문을 평가한다.
- Policy는 PG loss로, value network는 standard bootstrapping으로 jointly하게 학습한다.
Decoding at Inference Time
RL 학습을 통해서 모델은 long-term sequence 리워드를 최대화하도록 하였다. 해당 방법은 기존의 요약모델이 요약문을 생성하는 방식인 MLE-based 학습 방식과 상반된다. 결과적으로, RL-trained policy가 요약문을 생성할 때 기존의 beam search보다 더 효율적인 temperature sampling이 가능해졌다.
Result
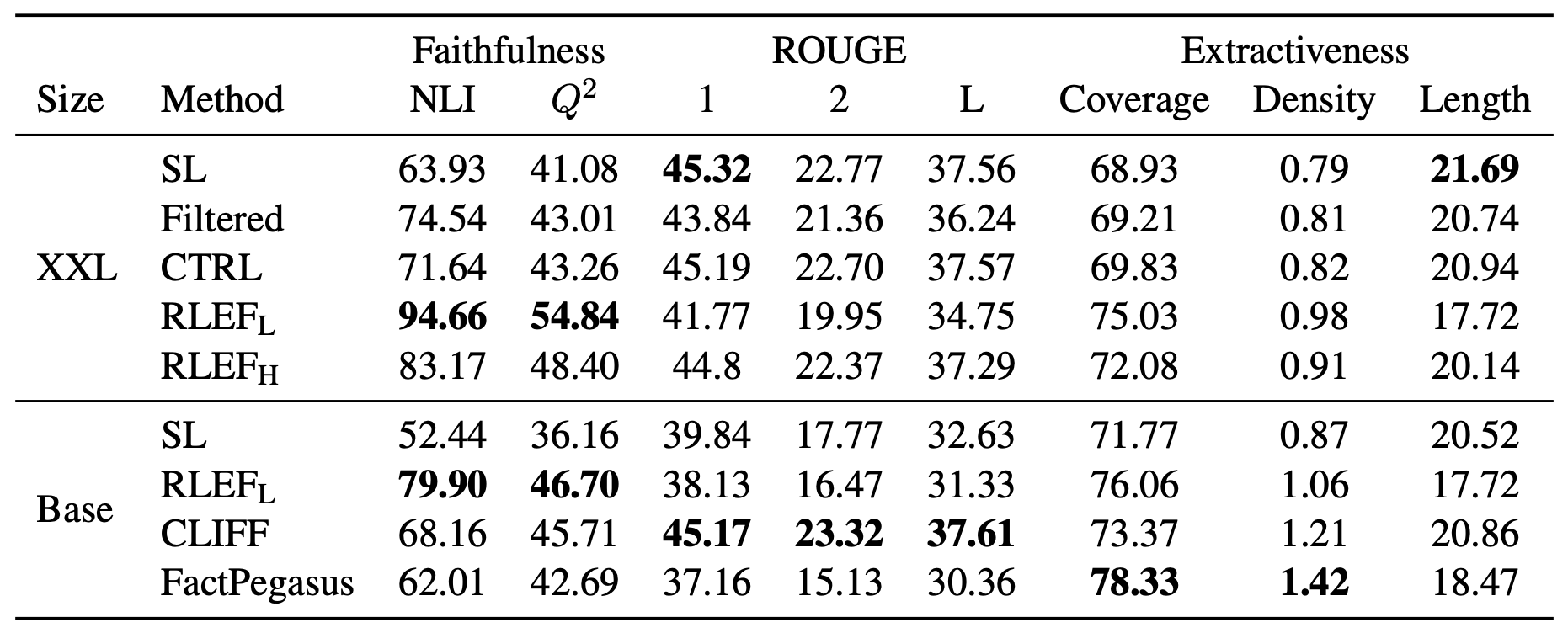
Factual consistency를 평가하기 위해서 NLI, $Q^2$ score를 사용했다. NLI는 NLI 분류기를 통해 요약문과 본문의 entailment 비율을 계산하고, $Q^2$은 QAGS나 QAGS와 유사하게 Q/A로 평가하는 방식이다. 또한 RL policy가 너무 faithfulness에 최적화되면 extractive한 경향을 띌수도 있기 때문에, Coverage와 Density 를 평가하는 extractiveness도 평가했다.
결과를 보면 RL-based 모델이 가장 높은 NLI와 $Q^2$ 점수를 얻었다. 반면에 ROUGE 점수는 낮은 것을 볼 수 있다. 약한 regularization을 준 RLEFL이 강한 regularization을 준 RLEFH보다 높은 factual consistency를 보이지만 더 낮은 ROUGE 점수를 보인다. 이를 통해 factual consistency를 향상시키기 위해서는 초기의 supervised 모델 시점에서 멀리 떨어져야하고, entailment 관계와 요약 특성은 trade-off 관계에 있다는 것을 알 수 있다. Density가 높은 것을 통해 RL policy가 원본 문서의 내용을 그대로 사용하지 않는다는 것을 의미하고 Coverage가 높은 것을 통해 원본 문서의 term들을 많이 사용하고 있다는 것을 보여주므로 hallucination이 적다는 것을 의미한다.
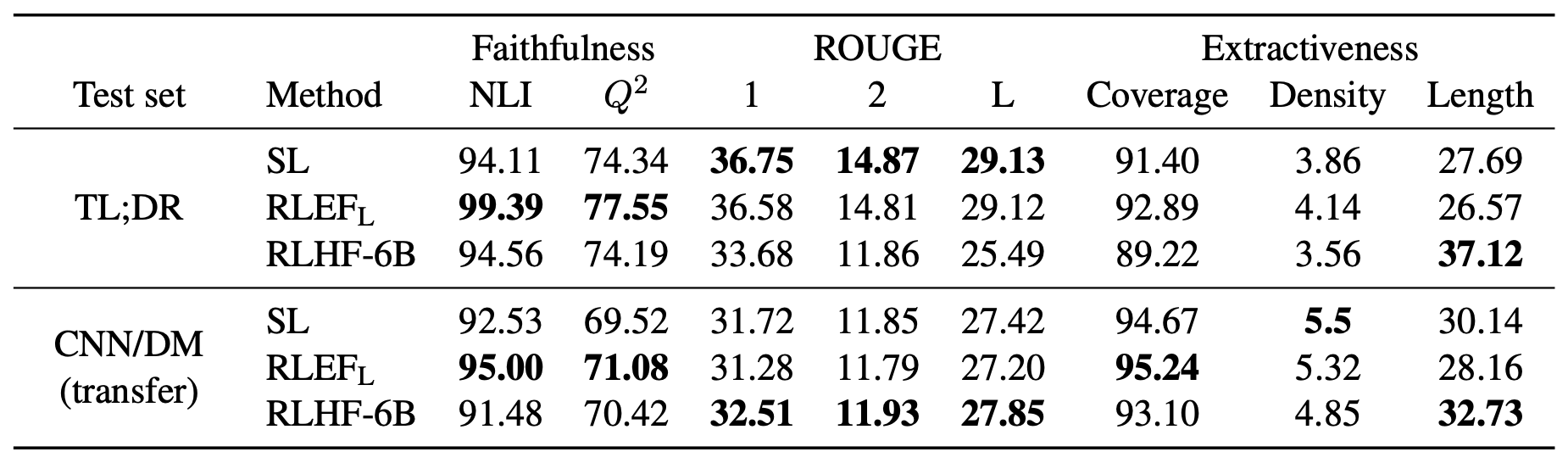
RLHF와의 비교도 진행을 하였는데, RLEFH가 RLHF에 비해서도 더 높은 NLI와 $Q^2$을 보인다. 또한 RLHF가 생성한 요약문은 baseline에 비해서 훨씬 긴 요약문을 생성한 반면 RLEFH가 생성한 요약문은 대체로 baseline과 비슷한 길이의 요약문을 생성하였다.
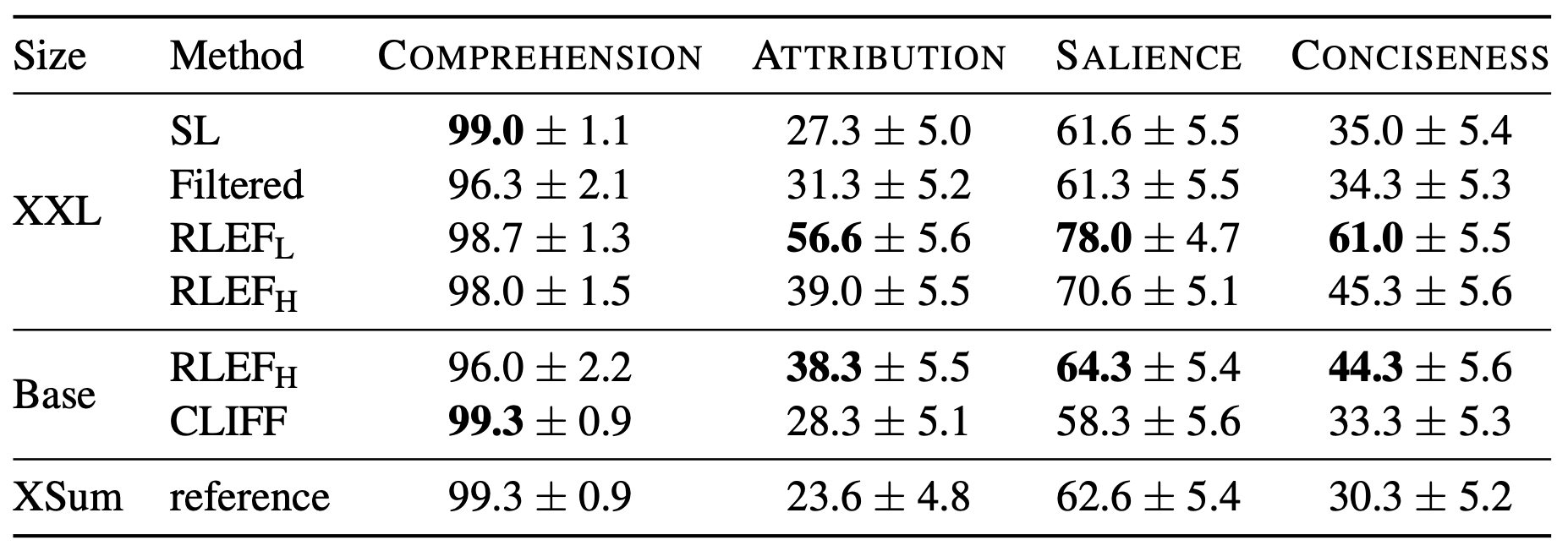
Human evaluation으로 4가지 항목: Comprehension, Attribution, Salience, Conciseness를 평가했다. Factual consistency를 의미하는 attribute항목에서 눈에 띄는 성능을 보여줄 뿐아니라 Salience와 Conciseness에서도 다른 모델들보다 좋은 성능을 보인다.
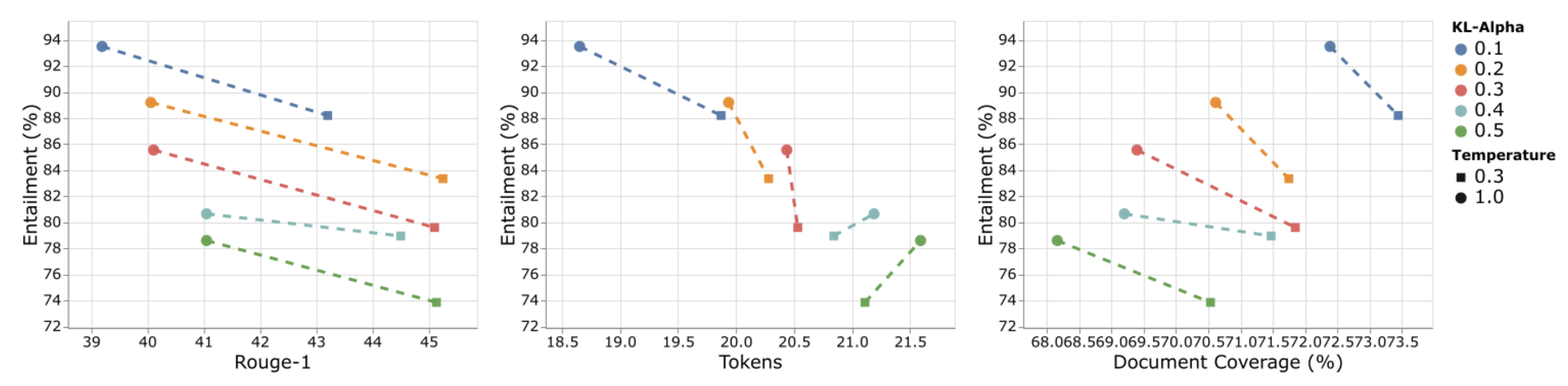
위의 figure에서 하이퍼파라미터의 ablation study를 보여준다. 먼저 높은 sampling temperature에서는 문장을 다양하게 생성하기 때문에 높은 entailment와 낮은 ROUGE를 보였다. 토큰의 길이에도 영향을 끼쳤는데, temperature가 높을 때 더 긴 요약문을 생성하였다.
Regularization term $\alpha$는 entailment와 trade-off를 가졌다. $\alpha$가 작을수록 높은 entailment를 보였고 낮은 ROUGE 점수, 높은 Coverage를 보였다. 이것은 document와 관계없는 hallucination이 줄어든 것으로 보인다.
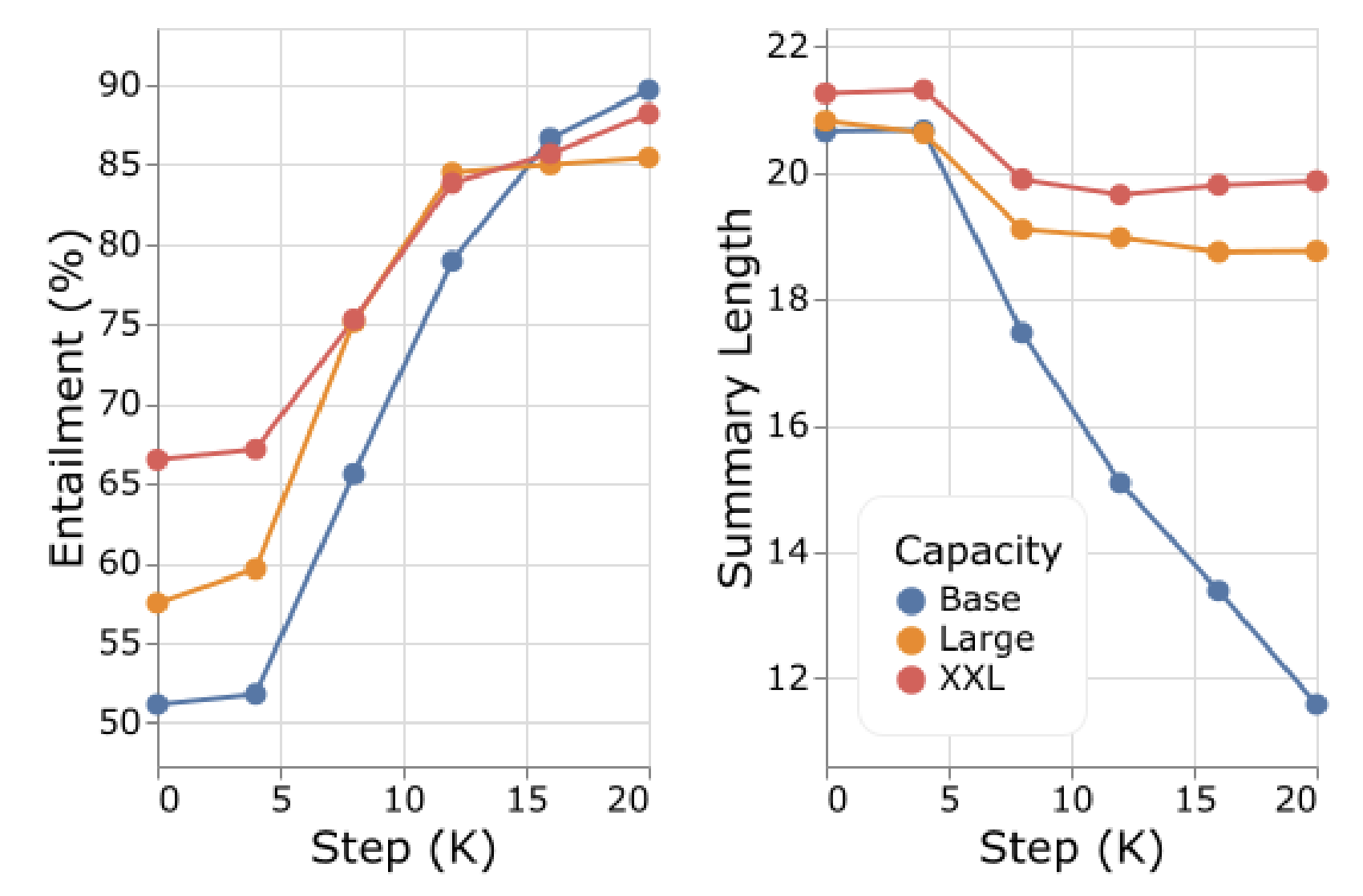
Large와 XXL 모델에서는 요약문의 길이가 많이 줄어들지 않았는데, Base 모델에서는 길이가 요약문의 길이가 굉장히 줄어들었다. 이것은 NLI 리워드로 부터 “hacking” 되었기 때문인데, 크기가 큰 모델들이 이러한 “hacking”으로부터 더 robust한 것을 볼 수 있다.
Limitation
해당 모델은 여러가지 문제점을 가지고 있다. 좋은 entailment model이 필요하고, 좋은 초기 요약 모델이 필요하다는 것이다. 리워드를 NLI를 통해서 주기 때문에, NLI 모델이 감지하지 못하는 문제들은 해결하지 못한다. 또한 초기 요약 모델이 좋은 성능을 보이지 않는다면 anchor 모델과의 유사도를 리워드로 줄 필요가 없다. 마지막 문제점은 RLEF를 위한 모델들의 사이즈가 커야만 한다. Robust한 결과를 내기 위해서는 요약 모델과 NLI 모델 모두 11B 크기의 모델을 사용했다.
Comment
Factually consistency를 높이기 위해서 NLI 태스크를 활용한 것이 재미있는 아이디어인 것 같다. 기존에 NLI 데이터 셋이 대부분 문장 단위로 이루어져있어서, 요약 분야에서는 활용하기 어려울 것으로 생각했는데, 해당 논문에서 사용한 ANLI의 경우 문서 단위로 구성되어 요약 분야에서 충분히 활용 가능할 것 같다. 또한 NLI 리워드와 anchor policy와의 KL distance를 trade-off 관계로 사용한 것이 굉장히 흥미로웠다. NLI 리워드의 경우 entailment 관계만을 보기 때문에 더 다양한 정보들이 없어지고, extractive하게 요약문을 생성하게 될 수 있는데, supervised 학습된 anchor model의 분포를 이용한다면 기존의 요약 모델이 가지고 있는 informative하고 abstractive한 성질을 유지할 수 있기 때문에, 이 값을 리워드에 함께 줌으로써, 적당한 균형을 유지하였다.
아쉬운 점으로는 NLI 데이터 셋으로 ANLI를 사용하였는데, 이 때 ANLI의 hypothesis가 한 줄로 구성되어있기 때문에, 요약문의 길이도 한 줄인 XSum과 같은 데이터 셋에서만 적용이 가능했다.